
中国企业报集团主管主办
中国企业信息交流平台


 中企网微博
中企网微博 中企网微信
中企网微信
中国企业报集团主管主办
中国企业信息交流平台
中企网微博中企网微信
现在制药 这事,人类要靠边站了。
坐标苏州 ,这是一个1600平的制药实验室,它的“打开方式”是这样的:
门口,没有人 。
走廊,没有人 。

实验室,也没有人 。

相比以往充斥着科学家、研究员的实验室,它更多的是把机械臂和AI系统 塞了进去,主打的就是一个全自动化 。
或许好奇的小伙伴就要问,这样的实验室能干嘛?就是为了自动化而自动化嘛?
事情当然没有那么简单,你瞧见的只是无人的操作,但在背后,AI做的可远远不只是替代人工的实验室操作那么简单,而是:
>14天内完成靶点发现和验证 ,还是全自动化干湿实验闭环的那种。
要知道,这个过程要放以前,可是需要足足2-3年才能完成……
而且更为精细化的工作,例如样本处理 、细胞培养 、化合物管理 、高通量筛选 、新一代测序 、高内涵成像 等等,不论是单一任务还是“联动”任务,机器都可以在AI的控制下轻松接手。

用Echo 650T制备检测板

用NovaSeq 6000测序
这便是来自全球AI制药第一梯队的“选手”——英矽智能 (Insilico Medicine)的第六代智能机器人实验室,也是全球首个用AI参与决策 的生物学实验室。
而在它背后驱动这一切的AI大脑 ,则是一个叫做PandaOmics 的平台,可以根据实验的进程自主做决策、下达指令。
若是把这个AI平台单拎出来,它更是囊括了20多种预测模型和生成生物学模型,还包含遗传学、蛋白质组学、甲基化数据、文本文献和科研基金等海量数据,用以支持专业的靶点识别、分析和排序、适应症探索等生物学研究。
甚至已经有高中生用PandaOmics发现了药物新靶点 ,并且研究成果还登上了国际学术期刊!
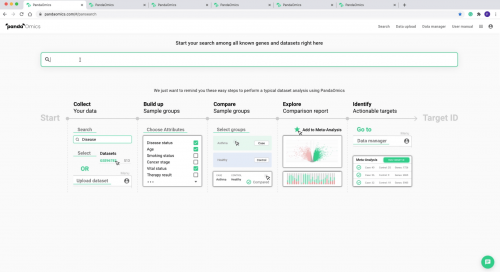
而且除了PandaOmics之外,英矽智能在人工智能制药领域拥有端到端的药物发现平台Pharma.AI,其中专注于化学领域的Chemistry42 还可以针对给定靶点从头设计具有特定属性药物理化性质的新型小分子。
这一切都可以在几小时内到几十小时内完成,且支持并行运行多个任务。
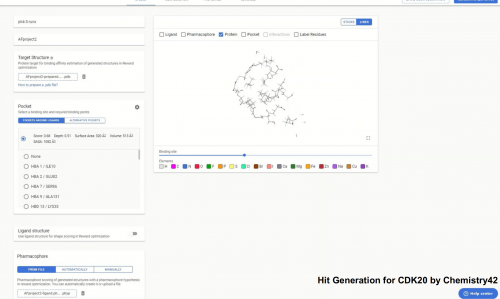

以及英矽智能还将科技圈最潮的大模型 也融入进来,在Pharma.AI的架构上推出Copilot系统 ,让你只要会对话就能使用专业的AI制药平台。。
由此可见,现在AI不仅是把制药这件事变成了“自动驾驶”模式 ,更是狠狠地把门槛打下去 、效率提上来 。
AI制药的流程和工作是方便了,但随之而来的一个问题便是:如此大的工作量,算力 ,又是如何解决的呢?
科学计算与AI,CPU都在发力
对于上述的问题,包括英矽智能、晶泰科技等AI制药的头部力量们不约而同地选择了相似的解决办法:
充分利用所有可以用、值得用的科学计算与AI算力平台。这种平台可不是你想象的那样被GPU制霸,相反,其中的CPU用量更大,尤其是英特尔的CPU 。
为什么要选择英特尔?
首要的一个原因,就是英特尔供企业计算及科学计算使用的主力CPU,即至强® 可扩展处理器系列产品,一直都是物理计算——无论是昔日计算机辅助制药,还是今天AI辅助制药都非常依赖的科学计算应用的关键承载平台。
另一方面,就算是把应用的主题从相对传统的制药相关的科学计算任务,切换到更偏AI的应用上,英特尔也算是颇有建树,这一点从它以AlphaFold2为代表的开源蛋白质预测模型的支持上就可见一斑。
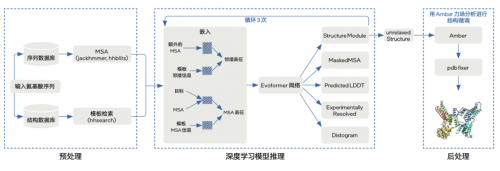
AlphaFold2基本架构
首先,AlphaFold2整个端到端的处理过程,涉及⼤量复杂多样的计算类型。从早期的数据收集、特征提取等预处理阶段,到基于深度学习的蛋白质结构预测,再到后续的结果分析,这是⼀个高度异构的工作负载。
而英特尔®至强® 可扩展处理器可以轻松胜任这一系列多样化的任务。以至强® CPU Max系列处理器为例,它采用全新微架构、更多内核(最高达56个),能以更高频率和更大缓存,去应对⾼通量的预处理和后处理工作。
它在内存和输入/输出(I/O)子系统性能上有着显著的增强,还结合大容量末级缓存使AlphaFold2推理过程中关键的张量吞吐获得了大幅提升。

英特尔® 至强® CPU Max 系列处理器
其次,由于AlphaFold2所采用的深度学习模型规模巨大,推理过程中的张量运算不仅量大,且维度极高。这就要求承载平台具备强⼤的AI运算加速能力。
在这⼀点上,新款至强® 系列处理器内置的英特尔® AMX(⾼级矩阵扩展)技术,可以显著加速大规模矩阵乘法运算。
在FP32/BF16混合精度计算下,其理论峰值可达每时钟周期1024次乘加操作。针对AlphaFold2推理任务中所需的大量矩阵运算操作,AMX_BF16能在保持较高精度的同时,提高计算速度并减少存储空间。
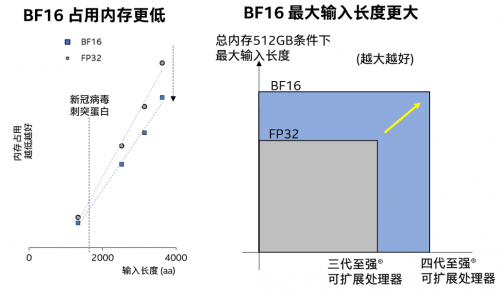
AMX_BF16推理优化带来更低内存占用和更大输入长度
另一方面,AlphaFold2因其高维张量运算和长序列并行计算,在推理过程中常⾯临超⼤内存需求,不光影响推理速度,还会限制更长蛋白质序列的预测。
为此英特尔从软硬协同的方式给出完整解决方案。
一面是提升内存容量和带宽。解决方案中,英特尔® 至强® CPU Max系列处理器除支持DDR5内存外,还集成了HBM(⾼带宽内存)。单颗处理器的HBM容量⾼达64GB,且具有高达460GB/s带宽。
另一面是提供了多种降低内存的软件优化方法。如面向PyTorch对张量计算原语(Tensor Processing Primitives,TPP)技术进行扩展,以及切分Attention模块和算子融合的推理优化方案,帮助AlphaFold2在通用矩阵乘法计算中所需的内存峰值大幅降低。
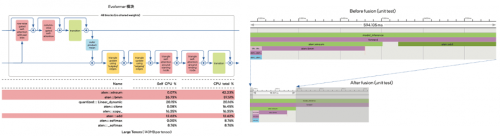
热点算子与融合效果
经过一系列加强和优化后,最终效果如何呢?
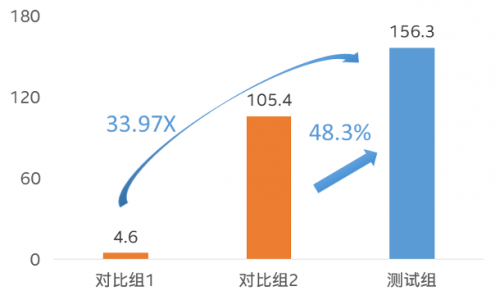
如图所示,在基于至强® CPU Max系列处理器的优化流程中,每个优化步骤获得的提升累积后,获得了相对于基线性能(对比组1,基于第三代至强® 可扩展处理器,未实施优化)高达33.97倍的通量提升。
根据测算,性能提升中的74%源自预处理阶段的高通量优化,26%要归功于对推理过程的优化。
此外,在同样开启IPEX(面向PyTorch的英特尔® 扩展优化框架)的情况下,相比对比组2(基于第三代至强® 可扩展处理器,但实施过优化),方案在升级使用至强® CPU Max 系列处理器后,其内置的HBM内存、英特尔® AMX的加成,则带来了48.3%的性能提升。
切分Attention模块和算子融合的推理优化方案
而且值得一提的是,在一项基于某公有云服务的测试中,基于至强® CPU平台构建的AlphaFold2解决方案还在性能上获得了远优于某高端GPU平台的表现,同时也优于由CPU+GPU混合构建的方案。
这可是一个非常难得的成绩——毕竟过去在很多AI应用的测试或实战中,CPU能有接近或媲美GPU的表现就已经算是成功,而AlphaFold2上至强® 平台则实现了性能+蛋白质预测序列长度的全面反超。
现在还剩下最后一个问题,多个蛋白结果的解析模型AlphaFold2 Multimer。
也就是从预测单个蛋白质三维结构,发展到了对多个蛋白质分子之间的相互作用及所形成的复合体结构进行预测。
CPU在这一演变过程中的支持力度如何呢?
答案是不用担心!基于英特尔® 架构的AlphaFold2解决方案同样也面向AlphaFold2 Multimer的管线结构进行了优化与验证,虽然后者的管线结构已根据蛋白质复合体结构预测的需求进行了调整,但英特尔AlphaFold2上的优化方案,在被用于AlphaFold2 Multimer时同样有效。
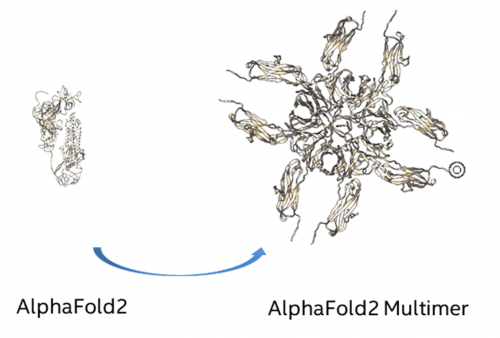
面向AlphaFold2 Multimer模式的方案实现
CPU加速新药发现不是梦
回顾以往,研发⼀种新药动辄需要10年时间,投入20亿美元才能起步。
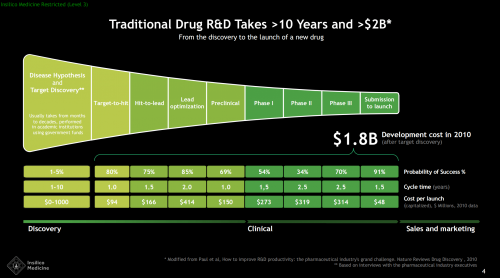
而在AI的助力下,这⼀成本正大幅降低。以英矽智能为例,它们进展最快的项目仅用18个月就找到了治疗特发性肺纤维化(IPF)的潜在全球首创候选药物并通过实验验证,总成本约为280万美元。
展望未来,随着AI技术的进⼀步发展渗透,它必将重塑制药业的创新模式,让新药研发变得更加高效、精准、经济。而在这⼀进程中,相关的科学计算及AI应用任务,依然需要有强大的算力支撑。
从英矽智能、晶泰科技等实践来看,以至强®处理器为代表的CPU平台,正凭借其在性能、成本、生态等方面的独特优势,成为推动AI时代制药创新的重要“引擎”。
这也预示着,CPU加速AI应用落地,帮助用户节支增效以及推进其技术和业务创新的脚步从未停止。
AI让新药研发进入“自动驾驶”模式,而英特尔®至强®处理器则提供了它所需的源源不断的动⼒。
在这种合作模式下,AI+制药还将擦出怎样的火花,就很值得期待了。
为了科普CPU在AI推理新时代的玩法,量子位开设了《最“in”AI》专栏,将从技术科普、行业案例、实战优化等多个角度全面解读。
我们希望通过这个专栏,让更多的人了解英特尔® 架构CPU在AI推理加速,甚至是整个AI平台或全流程加速上的实践成果,重点就是如何更好地利用CPU来提升AI,包括大模型应用的性能和效率。
未来随着英特尔AI产品技术组合的进一步扩展和丰富,我们还将在这里为大家提供更多产品技术上的优秀用例与方案分享,以及技术应用指南。
相关稿件
