
中国企业报集团主管主办
中国企业信息交流平台


 中企网微博
中企网微博 中企网微信
中企网微信
中国企业报集团主管主办
中国企业信息交流平台
中企网微博中企网微信
在数字经济浪潮中,数据就像“工业血液”的石油一样,其记录、存储、分析和应用的范围及规模前所未有,成为企业生存发展的核心驱动力。作为 “五大生产要素”之一,数据不仅是推动经济增长的新引擎,更是促进企业提升竞争力的关键资源。然而随着企业数据量的爆发式增长,尤其是非结构化数据的激增,如何高效访问、精准查询、智能管理这些数据,成为释放数据价值、加速数据要素化、市场化进程的重大挑战。
远光软件凭借其在光学字符识别(OCR)与深度学习算法领域的深厚积累,自主研发了融合NLP和大模型技术的图文识别智能底座。这一智能底座具有自学习、精准识别、智能数据提取的能力,能以标准类及定制类服务全方位满足各类业务场景下的文件处理、分类与信息提取等需求,显著提升业务处理的自动化、智能化水平。
通用场景:丰富的专有模型,更全面的通用票卡证识别
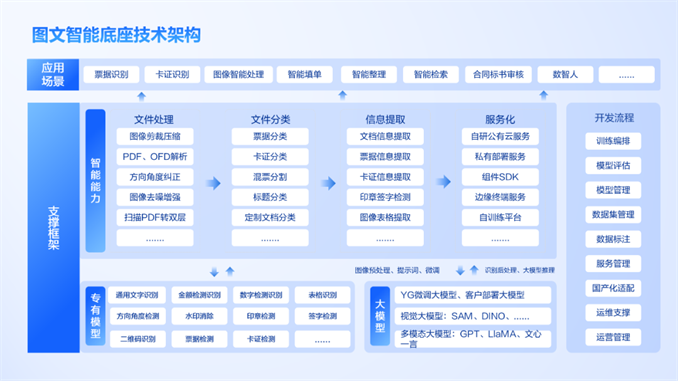
远光软件在长期服务央国企的过程中,沉淀了丰富的票据、卡证、表格等识别模型,如数电票、增值税发票、定额发票、机打发票、财政票据、营业执照、完税证明等超过36种。这些识别模型支持多种文件格式(JPG、PNG、PDF、OFD等)的识别、分类、关键字抽取等场景。可在业务现场通过公有云、私有云、一体机、边缘设备等快速部署,开箱即用,快速满足财务、营销、物资、设备、运行等多个领域业务场景对通用票证结构化数据提取需求。
定制场景:内置自研识别模型,识别更高效
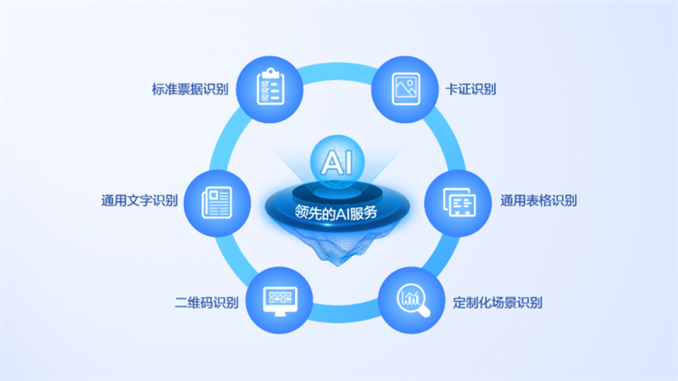
远光图文识别智能底座集数据管理、流程化标注、自动模型训练、模型评估、应用发布为一体,内置自主研发的表格、图像等识别模型,融入先进的模板学习和文本分析提取技术,支持版式文件类、文档流类、界面截图类文件的分析和识别,提供非固定版式票据信息提取、表格信息识别检索、附件快速分类分拣、附件材料完整性检查、文档信息定位抽取、文档内容基础推理计算、签字盖章快速检测定位等能力,打造从附件分类、材料完整性检查到文档内容推理计算的一站式解决方案。同时,通过服务接口方式,轻松赋能其他应用,加速业务创新。
大模型加持:泛化及扩展能力更强劲
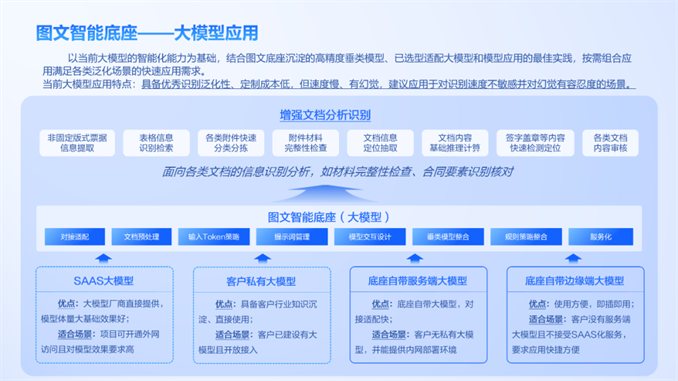
区别于传统OCR的“硬编码”方式,远光图文识别智能底座创新性地融入大语言模型。基于多年沉淀的元数据集对大语言模型进行微调,增强大语言模型对单据、卡证、表单等业务理解和推理能力,并通过合理设计提示词工程优化识别提取结果,实现信息提取的高效与精准,从而有效克服传统OCR泛化能力差、实现成本高的问题,提升系统的灵活性与扩展性。
延伸场景:软硬一体,信息采集更智能
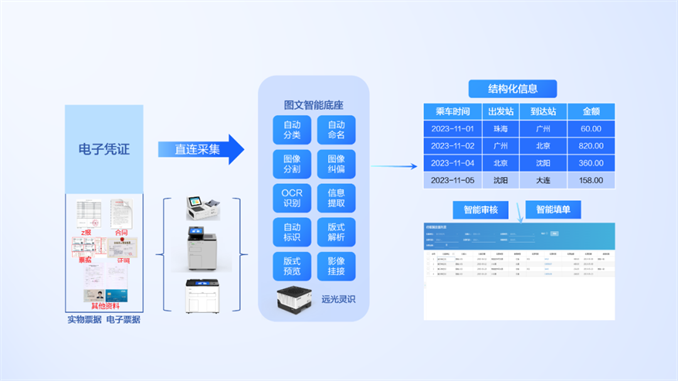
远光软件图文识别智能底座将训练达标后的识别模型以服务包的方式封装于远光灵识设备,通过即插即用模式为业务前端智能设备提供通用票据、定制表单、合同、卡证等电子文件的结构化信息提取,实现信息智能化采集,支撑业务处理和决策,充分发挥数据价值。
远光图文识别智能底座与智能票据协同终端协同,构建软硬一体智能化识别、查验、审核解决方案。在智能票据协同终端批量扫描纸质文件后,由图文识别智能底座进行结构化数据提取,通过RPA或API方式将提取的结构化数据与线上系统或电子表格已有数据进行核对,实时展示差异数据,实现线下与线上数据智能核验。该方案已广泛应用于营销销户退费检验、青苗补偿审核、劳务费发放核验、增值税专用发票抵扣联核验、项目决策清单核验等业财融合场景,有效减轻重复工作负担,规避人工误核、漏核造成的财务风险,提升审核质量与效率。
相关稿件
